


Como revisamos en el artículo de la semana pasada, una base de datos de vectores proporciona una solución superior para manejar incrustaciones de vectores al abordar las limitaciones de los índices de vectores independientes, como los desafíos de escalabilidad, los procesos de integración engorrosos y la ausencia de actualizaciones en tiempo real y medidas de seguridad integradas, lo que garantiza una mayor experiencia de gestión de datos eficaz y optimizada.
Las bases de datos vectoriales almacenan cadenas, números y otros tipos de datos escalares en filas y columnas. Por otro lado, una base de datos vectorial opera sobre vectores, por lo que la forma en que se optimiza y consulta es bastante diferente.
En las bases de datos tradicionales, generalmente consultamos filas en la base de datos donde el valor generalmente coincide exactamente con nuestra consulta. En las bases de datos vectoriales, aplicamos una métrica de similitud para encontrar un vector que sea el más similar a nuestra consulta.
Una base de datos vectorial utiliza una combinación de diferentes algoritmos que participan en la búsqueda del vecino más cercano aproximado (ANN). Estos algoritmos optimizan la búsqueda mediante hashing, cuantificación o búsqueda basada en gráficos.
Estos algoritmos se ensamblan en una canalización que proporciona una recuperación rápida y precisa de los vecinos de un vector consultado. Dado que la base de datos de vectores proporciona resultados aproximados , las principales ventajas y desventajas que consideramos son entre precisión y velocidad. Cuanto más preciso sea el resultado, más lenta será la consulta. Sin embargo, un buen sistema puede proporcionar una búsqueda ultrarrápida con una precisión casi perfecta.
Revisemos un workflow común para una base de datos vectorial:

- Indexación: la base de datos de vectores indexa vectores utilizando un algoritmo como PQ, LSH o HNSW (a continuación revisamos estos). Este paso asigna los vectores a una estructura de datos que permitirá una búsqueda más rápida.
- Consulta: la base de datos de vectores compara el vector de consulta indexado con los vectores indexados en el conjunto de datos para encontrar los vecinos más cercanos (aplicando una métrica de similitud utilizada por ese índice)
- Procesamiento posterior: en algunos casos, la base de datos vectorial recupera los vecinos más cercanos finales del conjunto de datos y los procesa posteriormente para devolver los resultados finales. Este paso puede incluir volver a clasificar a los vecinos más cercanos utilizando una medida de similitud diferente.
A continuación analizaremos cada uno de estos algoritmos con más detalle y revisamos cómo contribuyen al rendimiento general de una base de datos vectorial.
Algoritmos
Varios algoritmos pueden facilitar la creación de un índice vectorial. Su objetivo común es permitir consultas rápidas mediante la creación de una estructura de datos que se pueda recorrer rápidamente. Por lo general, transforman la representación del vector original en una forma comprimida para optimizar el proceso de consulta.
Hay soluciones de base de datos vectorial como Pinecone con el que no necesitas preocuparte por las complejidades y la selección de estos diversos algoritmos, ya que está diseñado para manejar todas las complejidades y decisiones algorítmicas detrás de escena, asegurando que obtengas el mejor rendimiento y resultados sin problemas.
Exploremos varios algoritmos y sus enfoques para manejar incrustaciones de vectores.
Proyección aleatoria (RP)
El algoritmo de proyección aleatoria, también conocido como Random Projection (RP), es una técnica utilizada para reducir la dimensionalidad de los datos de manera eficiente. Su objetivo principal es conservar la estructura y las relaciones entre los datos en un espacio de menor dimensión.
La idea detrás del algoritmo de proyección aleatoria se basa en la teoría de la dimensionalidad, que establece que un conjunto de datos de alta dimensionalidad puede ser proyectado a un espacio de menor dimensión sin perder demasiada información importante. En lugar de utilizar técnicas más costosas computacionalmente, como el análisis de componentes principales (PCA) o la descomposición de valores singulares (SVD), el algoritmo de proyección aleatoria utiliza una proyección aleatoria para lograr este objetivo.
El proceso del algoritmo de proyección aleatoria implica los siguientes pasos:
- Dado un conjunto de datos de alta dimensionalidad, se selecciona una matriz aleatoria de proyección. Esta matriz tiene dimensiones más bajas que los datos originales y se compone de números aleatorios generados de forma independiente.
- Los datos originales se multiplican por la matriz de proyección para obtener una proyección de menor dimensión.
- El resultado es una versión reducida de los datos originales que conserva ciertas propiedades estructurales y de similitud entre los puntos.
El algoritmo de proyección aleatoria es eficiente computacionalmente porque la multiplicación de la matriz de proyección es más rápida que las técnicas de reducción de dimensionalidad tradicionales. Además, tiene la propiedad deseable de preservar la estructura local de los datos, lo que significa que los puntos que son cercanos en el espacio de alta dimensión también serán cercanos en el espacio de menor dimensión.
Sin embargo, es importante tener en cuenta que el algoritmo de proyección aleatoria no siempre preserva todas las características importantes de los datos. Puede haber cierta pérdida de información, especialmente cuando se reduce significativamente la dimensionalidad. Por lo tanto, su efectividad puede variar dependiendo del conjunto de datos y del problema específico que se esté abordando.
Cuantificación del producto (PQ)
Otra forma de crear un índice es la cuantificación del producto (PQ), que es una técnica de compresión con pérdida para vectores de alta dimensión. Toma el vector original, lo divide en fragmentos más pequeños, simplifica la representación de cada fragmento mediante la creación de un "código" representativo para cada fragmento y luego vuelve a unir todos los fragmentos, sin perder información que es vital para las operaciones de similitud. El proceso de PQ se puede dividir en cuatro pasos: división, entrenamiento, codificación y consulta.
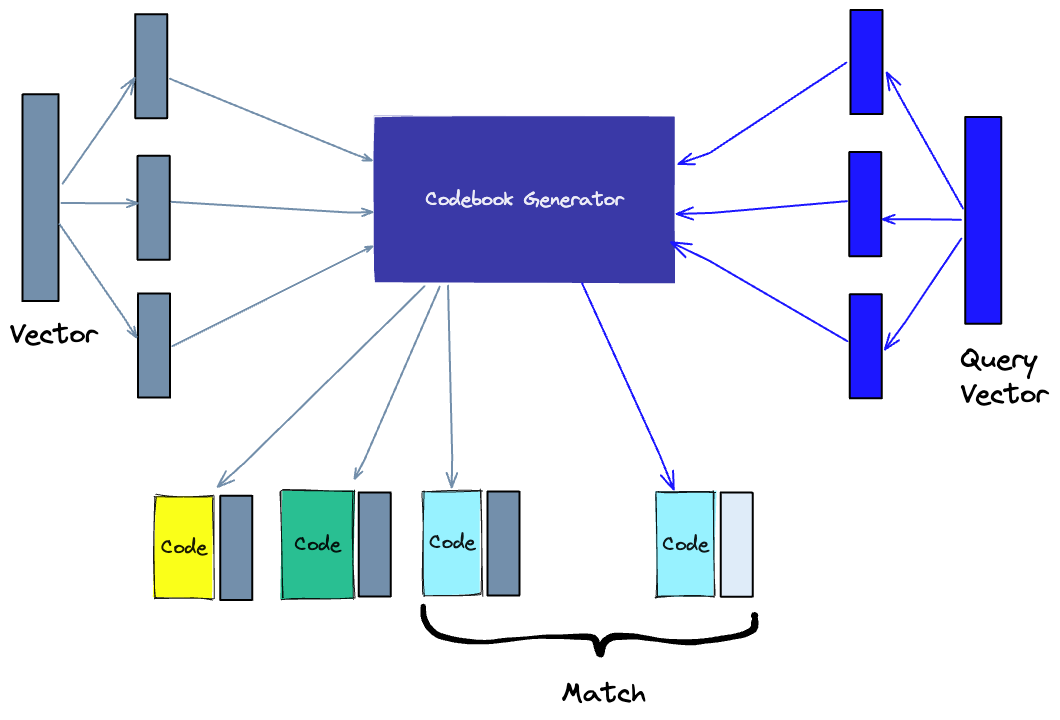
- División: los vectores se dividen en segmentos.
- Capacitación: construimos un "libro de códigos" para cada segmento. En pocas palabras, el algoritmo genera un grupo de "códigos" potenciales que podrían asignarse a un vector. En la práctica, este "libro de códigos" se compone de los puntos centrales de los grupos creados al realizar el agrupamiento de k-medias en cada uno de los segmentos del vector. Tendríamos el mismo número de valores en el libro de códigos del segmento que el valor que usamos para el agrupamiento de k-medias.
- Codificación: el algoritmo asigna un código específico a cada segmento. En la práctica, encontramos el valor más cercano en el libro de códigos a cada segmento de vector después de completar el entrenamiento. Nuestro código PQ para el segmento será el identificador del valor correspondiente en el libro de códigos. Podríamos usar tantos códigos PQ como quisiéramos, lo que significa que podemos seleccionar múltiples valores del libro de códigos para representar cada segmento.
- Consulta: cuando consultamos, el algoritmo descompone los vectores en subvectores y los cuantifica utilizando el mismo libro de códigos. Luego, usa los códigos indexados para encontrar los vectores más cercanos al vector de consulta.
El número de vectores representativos en el libro de códigos es una compensación entre la precisión de la representación y el costo computacional de buscar en el libro de códigos. Cuantos más vectores representativos haya en el libro de códigos, más precisa será la representación de los vectores en el subespacio, pero mayor será el coste computacional para buscar en el libro de códigos. Por el contrario, cuantos menos vectores representativos haya en el libro de códigos, menos precisa será la representación, pero menor será el coste computacional.
Hashing sensible a la localidad (LSH)
Locality-Sensible Hashing (LSH) es una técnica para indexar en el contexto de una búsqueda aproximada del vecino más cercano. Está optimizado para la velocidad sin dejar de ofrecer un resultado aproximado y no exhaustivo. LSH mapea vectores similares en "cubos" usando un conjunto de funciones hash, como se ve a continuación:

Para encontrar los vecinos más cercanos para un vector de consulta dado, usamos las mismas funciones hash que se usan para "agrupar" vectores similares en tablas hash. El vector de consulta se aplica a una tabla en particular y luego se compara con los otros vectores en esa misma tabla para encontrar las coincidencias más cercanas. Este método es mucho más rápido que buscar en todo el conjunto de datos porque hay muchos menos vectores en cada tabla hash que en todo el espacio.
Es importante recordar que LSH es un método aproximado y la calidad de la aproximación depende de las propiedades de las funciones hash. En general, cuantas más funciones hash se utilicen, mejor será la calidad de la aproximación. Sin embargo, el uso de una gran cantidad de funciones hash puede ser costoso desde el punto de vista computacional y puede no ser factible para grandes conjuntos de datos.
Hierarchical Navigable Small World (HNSW)
El algoritmo HNSW es un método utilizado para realizar búsquedas eficientes en bases de datos vectoriales de alta dimensionalidad. Fue propuesto como una alternativa a los árboles de búsqueda binaria y los árboles kd, que no funcionan de manera óptima en espacios de alta dimensionalidad.
El algoritmo HNSW se basa en la idea de construir una estructura jerárquica que organiza los datos en diferentes niveles. Cada nivel está compuesto por un conjunto de grafos, donde cada grafo es un conjunto de nodos conectados entre sí. Estos nodos representan los puntos de datos en la base de datos vectorial.
El proceso de construcción del algoritmo HNSW consta de los siguientes pasos:
- Se crea un grafo inicial con un nodo que representa un punto de datos seleccionado al azar de la base de datos.
- A continuación, se agregan más nodos a este grafo. Cada nuevo nodo se conecta a un conjunto de nodos existentes, utilizando una función de proximidad que mide la similitud entre los vectores de características de los puntos de datos.
- El proceso de agregación de nodos se repite hasta que se construye un grafo completo en un nivel determinado.
- Luego, se crea el siguiente nivel de la jerarquía, utilizando una función de selección de vecinos para conectar los nodos de un nivel con los del nivel inferior. Esta función garantiza que se mantenga una estructura jerárquica en los niveles superiores y permite la búsqueda rápida a través de la jerarquía.
- El proceso de construcción de niveles se repite hasta que se alcanza el nivel más bajo, que suele ser un grafo completo donde cada nodo está conectado con todos los demás nodos.

Una vez que se ha construido la estructura jerárquica del algoritmo HNSW, se puede utilizar para realizar búsquedas eficientes en la base de datos vectorial. El algoritmo permite realizar búsquedas aproximadas, donde se encuentran los puntos más cercanos a una consulta dada de manera rápida y con un buen nivel de precisión.
Medidas de similitud
Sobre la base de los algoritmos revisados, necesitamos comprender el papel de las medidas de similitud en las bases de datos vectoriales. Estas medidas son la base de cómo una base de datos vectorial compara e identifica los resultados más relevantes para una consulta determinada.
Las medidas de similitud son métodos matemáticos para determinar qué tan similares son dos vectores en un espacio vectorial. Las medidas de similitud se utilizan en las bases de datos vectoriales para comparar los vectores almacenados en la base de datos y encontrar los que son más similares a un vector de consulta dado.
Se pueden usar varias medidas de similitud, que incluyen:
- Semejanza de coseno: mide el coseno del ángulo entre dos vectores en un espacio vectorial. Va de -1 a 1, donde 1 representa vectores idénticos, 0 representa vectores ortogonales y -1 representa vectores que son diametralmente opuestos.
- Distancia euclidiana: mide la distancia en línea recta entre dos vectores en un espacio vectorial. Va de 0 a infinito, donde 0 representa vectores idénticos y los valores más grandes representan vectores cada vez más diferentes.
- Producto punto: mide el producto de las magnitudes de dos vectores y el coseno del ángulo entre ellos. Va de -∞ a ∞, donde un valor positivo representa vectores que apuntan en la misma dirección, 0 representa vectores ortogonales y un valor negativo representa vectores que apuntan en direcciones opuestas.
La elección de la medida de similitud tendrá un efecto sobre los resultados obtenidos a partir de una base de datos vectorial. También es importante tener en cuenta que cada medida de similitud tiene sus propias ventajas y desventajas, y es importante elegir la correcta según el caso de uso y los requisitos.
Filtros
Cada vector almacenado en la base de datos también incluye metadatos. Además de la capacidad de consultar vectores similares, las bases de datos vectoriales también pueden filtrar los resultados en función de una consulta de metadatos. Para ello, la base de datos vectorial suele mantener dos índices: un índice vectorial y un índice de metadatos. A continuación, realiza el filtrado de metadatos antes o después de la búsqueda de vectores, pero en cualquier caso, existen dificultades que hacen que el proceso de consulta se ralentice.
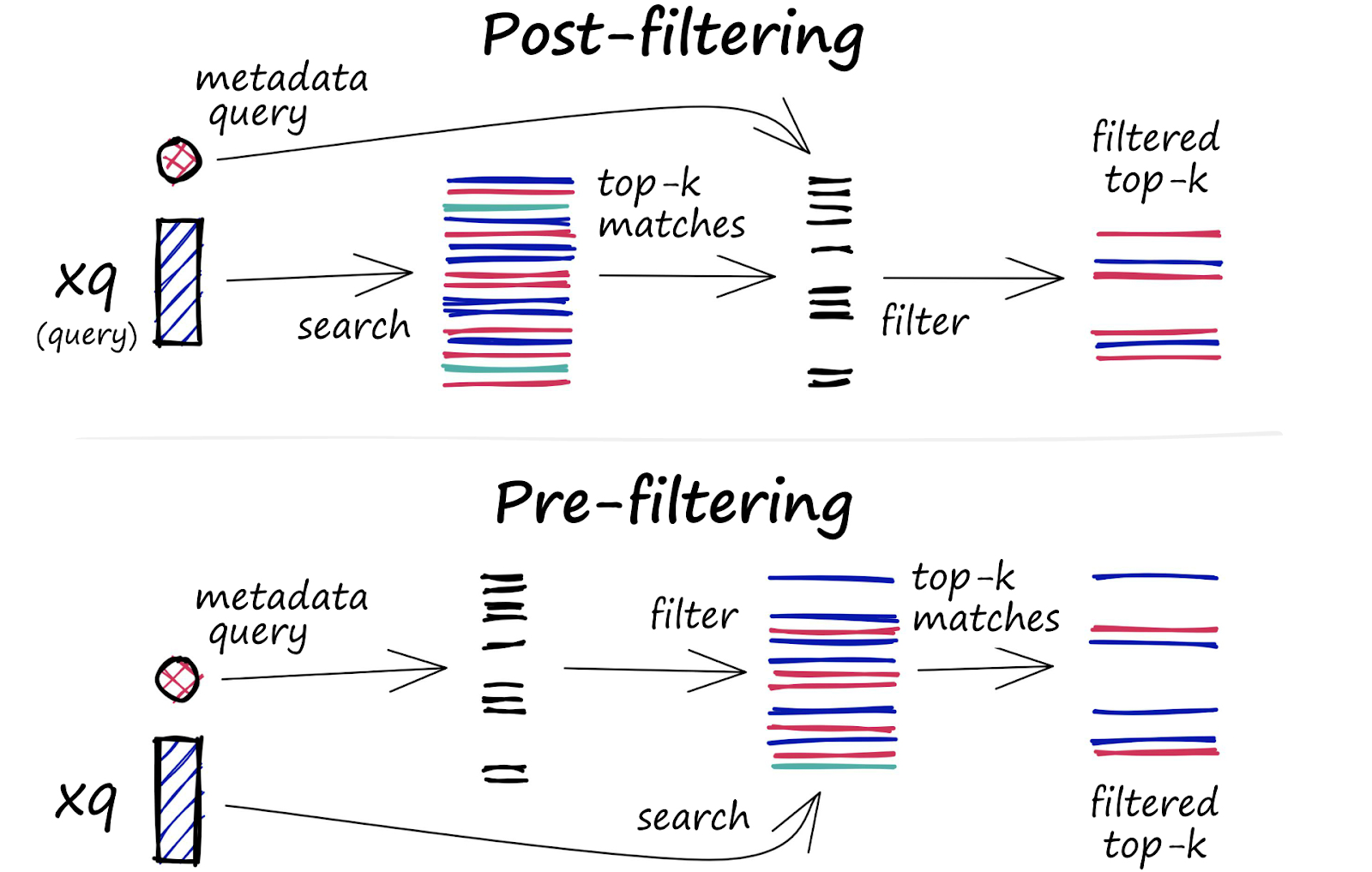
El proceso de filtrado se puede realizar antes o después de la búsqueda de vectores, pero cada enfoque tiene sus propios desafíos que pueden afectar el rendimiento de la consulta:
- Prefiltrado: en este enfoque, el filtrado de metadatos se realiza antes de la búsqueda de vectores. Si bien esto puede ayudar a reducir el espacio de búsqueda, también puede hacer que el sistema pase por alto resultados relevantes que no coinciden con los criterios del filtro de metadatos. Además, el filtrado extenso de metadatos puede ralentizar el proceso de consulta debido a la sobrecarga computacional adicional.
- Post-filtrado: En este enfoque, el filtrado de metadatos se realiza después de la búsqueda de vectores. Esto puede ayudar a garantizar que se consideren todos los resultados relevantes, pero también puede generar una sobrecarga adicional y ralentizar el proceso de consulta, ya que los resultados irrelevantes deben filtrarse una vez que se completa la búsqueda.
Para optimizar el proceso de filtrado, las bases de datos vectoriales utilizan varias técnicas, como el aprovechamiento de métodos de indexación avanzados para metadatos o el uso de procesamiento paralelo para acelerar las tareas de filtrado. Equilibrar las compensaciones entre el rendimiento de la búsqueda y la precisión del filtrado es esencial para proporcionar resultados de consulta eficientes y relevantes en las bases de datos vectoriales.
Operaciones de base de datos
A diferencia de los índices vectoriales, las bases de datos vectoriales están equipadas con un conjunto de capacidades que las hacen más calificadas para su uso en entornos de producción a gran escala. Echemos un vistazo a una descripción general de los componentes que intervienen en el funcionamiento de la base de datos.
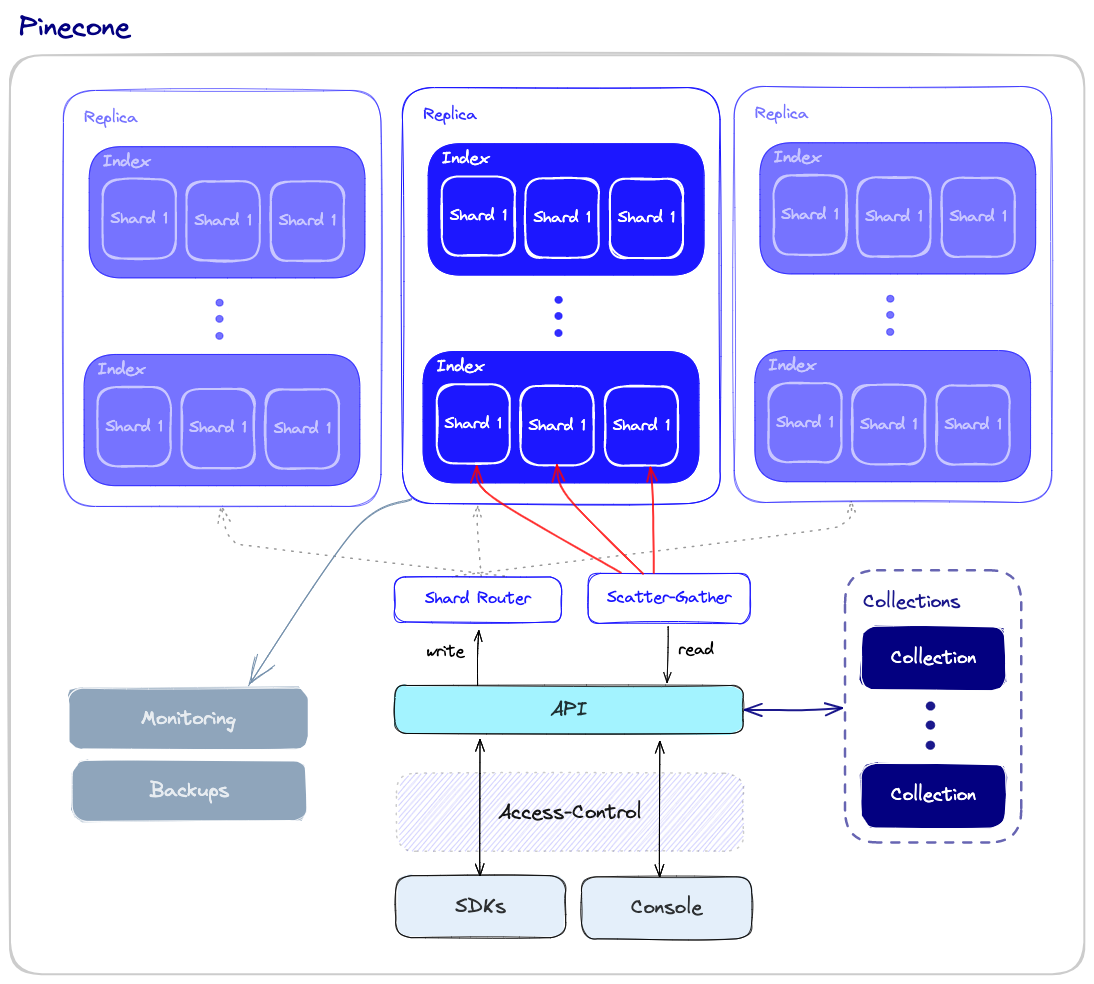
Rendimiento y tolerancia a fallas
El rendimiento y la tolerancia a fallos están estrechamente relacionados. Cuantos más datos tengamos, más nodos se requerirán, y mayores posibilidades de errores y fallas. Como es el caso con otros tipos de bases de datos, queremos asegurarnos de que las consultas se ejecuten lo más rápido posible, incluso si fallan algunos de los nodos subyacentes. Esto podría deberse a fallas de hardware, fallas de red u otros tipos de errores técnicos. Este tipo de falla podría provocar tiempo de inactividad o incluso resultados de consulta incorrectos.
Para garantizar tanto el alto rendimiento como la tolerancia a fallas, las bases de datos vectoriales usan fragmentación y la replicación aplica lo siguiente:
- Fragmentación: partición de los datos en varios nodos. Existen diferentes métodos para particionar los datos; por ejemplo, se pueden particionar por la similitud de diferentes grupos de datos para que los vectores similares se almacenen en la misma partición. Cuando se realiza una consulta, se envía a todos los fragmentos y los resultados se recuperan y combinan. Esto se llama el patrón de "scatter-gather".
- Replicación: creación de múltiples copias de los datos en diferentes nodos. Esto asegura que incluso si un nodo en particular falla, otros nodos podrán reemplazarlo. Hay dos modelos principales de consistencia: consistencia eventual y consistencia fuerte. La consistencia eventual permite inconsistencias temporales entre diferentes copias de los datos, lo que mejorará la disponibilidad y reducirá la latencia, pero puede generar conflictos e incluso la pérdida de datos. Por otro lado, una consistencia sólida requiere que todas las copias de los datos se actualicen antes de que se considere completa una operación de escritura. Este enfoque proporciona una consistencia más sólida, pero puede resultar en una latencia más alta.
Supervisión
Para administrar y mantener de manera efectiva una base de datos de vectores, necesitamos un sistema de monitoreo sólido que rastree los aspectos importantes del rendimiento, la salud y el estado general de la base de datos. El monitoreo es fundamental para detectar problemas potenciales, optimizar el rendimiento y garantizar operaciones de producción sin problemas. Algunos aspectos del monitoreo de una base de datos de vectores incluyen los siguientes:
- Uso de recursos: monitorear el uso de recursos, como CPU, memoria, espacio en disco y actividad de red, permite identificar posibles problemas o restricciones de recursos que podrían afectar el rendimiento de la base de datos.
- Rendimiento de consultas: la latencia de consultas, el rendimiento y las tasas de error pueden indicar posibles problemas sistémicos que deben abordarse.
- Estado del sistema: la supervisión general del estado del sistema incluye el estado de los nodos individuales, el proceso de replicación y otros componentes críticos.
Control de acceso
El control de acceso es el proceso de administrar y regular el acceso de los usuarios a los datos y recursos. Es un componente vital de la seguridad de los datos, ya que garantiza que solo los usuarios autorizados tengan la capacidad de ver, modificar o interactuar con datos confidenciales almacenados en la base de datos vectorial.
El control de acceso es importante por varias razones:
- Protección de datos: dado que las aplicaciones de IA a menudo manejan información sensible y confidencial, la implementación de mecanismos estrictos de control de acceso ayuda a proteger los datos de accesos no autorizados y posibles infracciones.
- Cumplimiento: muchas industrias, como la atención médica y las finanzas, están sujetas a estrictas normas de privacidad de datos. La implementación de un control de acceso adecuado ayuda a las organizaciones a cumplir con estas regulaciones, protegiéndolas de repercusiones legales y financieras.
- Auditoría: Los mecanismos de control de acceso permiten a las organizaciones mantener un registro de las actividades de los usuarios dentro de la base de datos de vectores. Esta información es crucial para fines de auditoría, y cuando ocurren violaciones de seguridad, ayuda a rastrear cualquier acceso o modificación no autorizados.
- Escalabilidad y flexibilidad: a medida que las organizaciones crecen y evolucionan, sus necesidades de control de acceso pueden cambiar. Un sólido sistema de control de acceso permite modificar y ampliar sin problemas los permisos de los usuarios, lo que garantiza que la seguridad de los datos permanezca intacta durante el crecimiento de la organización.
Copias de seguridad y colecciones
Cuando todo lo demás falla, las bases de datos vectoriales ofrecen la posibilidad de confiar en copias de seguridad creadas con regularidad. Estas copias de seguridad se pueden almacenar en sistemas de almacenamiento externo o servicios de almacenamiento basados en la nube, lo que garantiza la seguridad y la capacidad de recuperación de los datos. En caso de pérdida o corrupción de datos, estas copias de seguridad se pueden usar para restaurar la base de datos a un estado anterior, lo que minimiza el tiempo de inactividad y el impacto en el sistema en general.
API y SDK
Interactuar con una API permite que la interacción con la base de datos sea familiar y cómodo. Al proporcionar una interfaz fácil de usar, la capa API de la base de datos de vectores simplifica el desarrollo de aplicaciones de búsqueda de vectores de alto rendimiento.
Además de la API, las bases de datos vectoriales suelen proporcionar SDK específicos del lenguaje de programación que envuelven la API. Los SDK facilitan aún más a los desarrolladores la interacción con la base de datos en las aplicaciones. Esto te permite concentrarte en los casos de uso específicos, como la búsqueda de texto semántico, la respuesta a preguntas generativas, la búsqueda híbrida, la búsqueda por similitud de imágenes o las recomendaciones de productos, sin tener que preocuparse por las complejidades de la infraestructura subyacente.
Conclusión
El crecimiento exponencial de las incrustaciones de vectores en campos como la PNL y otras aplicaciones de IA ha resultado en bases de datos vectoriales como el motor de cómputo que nos permite interactuar de manera efectiva con las incrustaciones de vectores en las aplicaciones.
Las bases de datos vectoriales son bases de datos especialmente diseñadas que están especializadas para abordar los problemas que surgen al administrar incrustaciones de vectores en escenarios de producción. Por esa razón, ofrecen ventajas significativas sobre las bases de datos tradicionales basadas en escalares y los índices vectoriales independientes.







