


El procesamiento de datos eficiente se ha vuelto más crucial que nunca para las aplicaciones que involucran grandes modelos de lenguaje, IA generativa y búsqueda semántica.
Todas estas nuevas aplicaciones se basan en la incrustación ‘embedding’ de vectores, un tipo de representación de datos que contiene información semántica que es crítica para que la IA obtenga comprensión y mantenga una memoria a largo plazo que pueda utilizar al ejecutar tareas complejas.
Las incrustaciones, ‘embedding’ en terminología técnica, son generados por modelos de IA y tienen una gran cantidad de atributos o características, lo que hace que su representación sea difícil de administrar. En el contexto de la IA y el aprendizaje automático, estas características representan diferentes dimensiones de los datos que son esenciales para comprender patrones, relaciones y estructuras subyacentes.
Por eso necesitamos una base de datos especializada diseñada específicamente para manejar este tipo de datos. Las bases de datos vectoriales cumplen con este requisito al ofrecer capacidades optimizadas de almacenamiento y consulta para incrustaciones. Las bases de datos vectoriales tienen las capacidades de una base de datos tradicional que están ausentes en los índices vectoriales independientes y la especialización de tratar con incrustaciones de vectores, de las que carecen las bases de datos tradicionales basadas en escalares.
El desafío de trabajar con incrustaciones de vectores es que las bases de datos tradicionales basadas en escalares no pueden mantenerse al día con la complejidad y la escala de dichos datos, lo que dificulta la extracción de información y la realización de análisis en tiempo real. Ahí es donde entran en juego las bases de datos vectoriales: están diseñadas intencionalmente para manejar este tipo de datos y ofrecer el rendimiento, la escalabilidad y la flexibilidad que necesita para aprovechar al máximo sus datos.
Con una base de datos vectorial, podemos agregar funciones avanzadas a nuestras IA, como recuperación de información semántica, memoria a largo plazo y más. El siguiente diagrama nos da una mejor comprensión del papel de las bases de datos vectoriales en este tipo de aplicación:
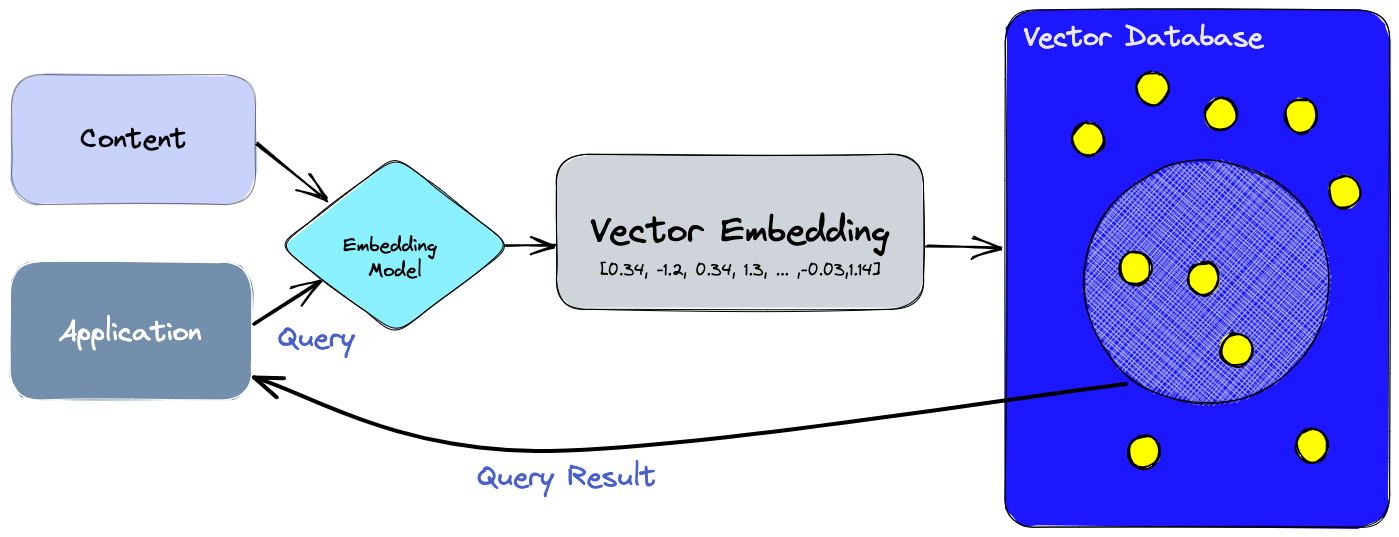
- Primero, usamos el modelo de incrustación para crear incrustaciones de vectores para el contenido que queremos indexar.
- La incrustación de vectores se inserta en la base de datos de vectores, con alguna referencia al contenido original a partir del cual se creó la incrustación.
- Cuando la aplicación emite una consulta, usamos el mismo modelo de incrustación para crear incrustaciones para la consulta y usamos esas incrustaciones para consultar la base de datos en busca de incrustaciones de vectores similares. Y como se mencionó anteriormente, esas incrustaciones similares están asociadas con el contenido original que se usó para crearlas.
¿Cuál es la diferencia entre un índice vectorial y una base de datos vectorial?
Los índices de vectores independientes como FAISS (Facebook AI Similarity Search) pueden mejorar significativamente la búsqueda y recuperación de incrustaciones de vectores, pero carecen de las capacidades que existen en cualquier base de datos. Las bases de datos vectoriales, por otro lado, están diseñadas específicamente para administrar incrustaciones de vectores, lo que brinda varias ventajas sobre el uso de índices vectoriales independientes:
- Gestión de datos: las bases de datos vectoriales ofrecen funciones conocidas y fáciles de usar para el almacenamiento de datos, como insertar, eliminar y actualizar datos. Esto hace que administrar y mantener datos vectoriales sea más fácil que usar un índice vectorial independiente como FAISS, que requiere trabajo adicional para integrarse con una solución de almacenamiento.
- Almacenamiento y filtrado de metadatos: las bases de datos vectoriales pueden almacenar metadatos asociados con cada entrada de vector. Luego, los usuarios pueden consultar la base de datos utilizando filtros de metadatos adicionales para consultas más detalladas.
- Escalabilidad: las bases de datos vectoriales están diseñadas para escalar con volúmenes de datos crecientes y demandas de los usuarios, lo que brinda un mejor soporte para el procesamiento paralelo y distribuido. Los índices vectoriales independientes pueden requerir soluciones personalizadas para lograr niveles similares de escalabilidad (como implementarlos y administrarlos en clústeres de Kubernetes u otros sistemas similares).
- Actualizaciones en tiempo real: las bases de datos vectoriales a menudo admiten actualizaciones de datos en tiempo real, lo que permite cambios dinámicos en los datos, mientras que los índices vectoriales independientes pueden requerir un proceso completo de reindexación para incorporar nuevos datos, lo que puede llevar mucho tiempo y ser computacionalmente costoso.
- Copias de seguridad y colecciones: las bases de datos vectoriales manejan la operación rutinaria de hacer una copia de seguridad de todos los datos almacenados en la base de datos.
- Integración del ecosistema: las bases de datos vectoriales pueden integrarse más fácilmente con otros componentes de un ecosistema de procesamiento de datos, como canalizaciones ETL (como Spark), herramientas de análisis (como Tableau y Segment ) y plataformas de visualización (como Grafana ), lo que simplifica el flujo de trabajo de administración de datos. También permite una fácil integración con otras herramientas relacionadas con la IA como LangChain, LlamaIndex y los complementos de ChatGPT .
- Seguridad de datos y control de acceso: las bases de datos vectoriales suelen ofrecer funciones integradas de seguridad de datos y mecanismos de control de acceso para proteger la información confidencial, que pueden no estar disponibles en soluciones de índices vectoriales independientes.
Conclusión
Una base de datos de vectorial proporciona una solución superior para manejar incrustaciones de vectores al abordar las limitaciones de los índices de vectores independientes, como los desafíos de escalabilidad, los procesos de integración engorrosos y la ausencia de actualizaciones en tiempo real y medidas de seguridad integradas, lo que garantiza una mayor experiencia de gestión de datos eficaz y optimizada.







