


Hace 3 años Chiyana nos compartía un artículo donde se preguntaba ¿Por qué puede ser buena idea evitar el incremento automático en SQL?, donde describe los beneficios del uso de los UUIDs.
Es por ello que hoy quiero quiero compartirte un análisis sobre el uso de claves como identificadores únicos en una configuración distribuida y su impacto en el rendimiento de escritura.
El uso de números enteros ordenados que no se repiten y se incrementan automáticamente ha sido una práctica común para definir claves primarias en bases de datos relacionales. Este tipo de clave ha tenido éxito porque satisface los dos requisitos de indexación más importantes.
1. Son únicos, por lo que pueden identificarse de forma única.
2. Están ordenados y clasificables, por lo que se pueden indexar de manera eficiente.
Cuando la base de datos es una entidad monolítica, este tipo de clave es ideal. Sin embargo, tan pronto como decidimos escalar y pasar a una configuración distribuida como podrían ser sistemas basados en microservicios, esto ya no es único, esto se debe a que ahora varias entidades comienzan a generar números de incremento automático.
Impacto en los índices agrupados durante las escrituras
Antes de pasar a discutir alternativas a los números enteros incrementados automáticamente como identificadores únicos, intentemos comprender cómo se ven afectados los índices cuando las bases de datos relacionales escriben datos nuevos.
Los índices agrupados generalmente se representan en una estructura de datos de Árbol-B. Tienen varios beneficios que los hacen muy adecuados para su uso en índices agrupados.
- Eficiente en la búsqueda de datos: los árboles-B están diseñados para ser eficientes en la búsqueda de datos, incluso en grandes conjuntos de datos. Utilizan una estructura jerárquica que permite un recorrido rápido de los datos, lo que reduce la cantidad de operaciones de E/S de disco necesarias para encontrar un valor específico.
- Los árboles-B están equilibrados: son estructuras de datos autoequilibradas, lo que significa que mantienen una estructura de árbol equilibrada incluso cuando se insertan o eliminan datos. Esto ayuda a garantizar que la altura del árbol permanezca relativamente constante, lo que mejora el rendimiento y reduce el riesgo de que los datos se vuelvan inaccesibles.
- Los árboles-B admiten consultas de rango: pueden admitir consultas de rango, lo que significa que se pueden usar para encontrar de manera eficiente todos los valores que se encuentran dentro de un rango específico. Esto es útil en escenarios en los que necesita encontrar todos los registros que se encuentran dentro de un cierto rango de valores para una columna en particular.
En la mayoría de los casos, en las bases de datos relacionales, se permite tener solo 1 índice agrupado por tabla, esto se debe a que la organización física de los datos está controlada por el índice agrupado (por las columnas en las que se crea el índice, generalmente la clave principal).
En MSSQL, al escribir datos en una tabla, el motor de la base de datos incluye escrituras lógicas y físicas. Una escritura lógica es cuando los datos se modifican en una página en el caché del búfer y se marcan como sucios. Una escritura física es cuando se escribe una página sucia desde el caché del búfer al disco. Dado que las escrituras lógicas no se escriben inmediatamente en el disco, puede haber más de una escritura lógica en una página en la memoria caché del búfer siempre que el registro esté destinado a escribirse en esa página (determinado por el índice agrupado).

El motor de la base de datos primero debe determinar la página correcta para almacenar la nueva fila de datos según el índice agrupado. Para hacer esto, generalmente realiza una búsqueda binaria en el índice para identificar la página correcta, una vez que se identifica la página, necesita leer la página del disco en el caché del búfer, esto solo es necesario si la página no está presente en el caché de búfer.
Si la clave del índice agrupado cumple con los requisitos de indexación discutidos anteriormente, las escrituras posteriores no requerirán la lectura de páginas del disco físico, ya que en la mayoría de los casos estarán disponibles en la memoria caché del búfer debido a una escritura anterior en poco tiempo leyéndolo en el búfer.
Tan pronto como comienzas a usar una columna que no está ordenada (durante la generación) para un índice agrupado; Significa que los datos almacenados en la tabla requieren trabajo adicional para organizarse en un orden lógico, lo que daría como resultado un rendimiento de escritura deficiente.
Identificadores únicos alternativos en un entorno distribuido
Identificador único universal (UUID)
Los UUID son cadenas largas de 128 bits que pueden garantizar la singularidad en el espacio y el tiempo. Son ampliamente utilizados para identificar recursos de forma única. Hay varias versiones de UUID, cada una con un formato ligeramente diferente. La versión de UUID más utilizada es la 4.

La especificación detallada de UUID se puede encontrar en RFC 4122 .
UUID en una configuración distribuida permite la unicidad, pero no son tan buenos para el rendimiento de escritura y he aquí por qué.
Los UUID son cadenas aleatorias (en la mayoría de las versiones) que no tienen un orden particular en una generación. Cuando los usa para una columna de índice agrupado, deben ordenarse y almacenarse. Dado que no están ordenados (naturalmente durante la generación), se requiere más E/S para almacenarlos en la página correcta, lo que podría resultar en un rendimiento de escritura deficiente en tablas grandes y podría generar problemas como la fragmentación del índice, ya que las páginas de datos pueden no estar en orden contiguo.
Identificador universalmente único clasificable lexicográficamente (ULID)
Como sugiere el título, los ULID son identificadores universalmente únicos pero clasificables lexicográficamente, esta es principalmente la razón por la cual es mejor en el rendimiento de escritura a escala en comparación con los UUID. Los ULID son una forma relativamente nueva de identificadores y aún carecen de soporte nativo generalizado.
ULID se genera en 2 componentes:
1. Marca de tiempo: número entero de 48 bits con el tiempo UNIX en milisegundos
2. Aleatoriedad: cadena aleatoria de 80 bits
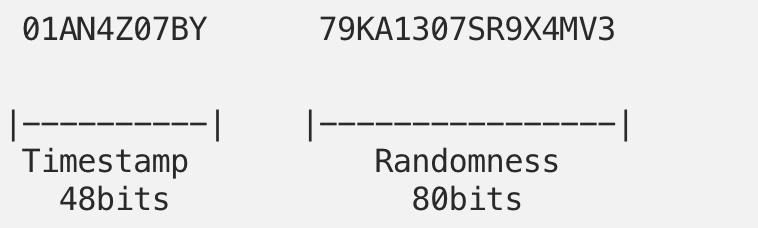
En total, son una cadena única de 128 bits de largo pero clasificable lexicográficamente. ULID se codifica mediante una combinación de caracteres binarios y base32, lo que da como resultado un formato de 26 caracteres más compacto en comparación con los 36 caracteres generados por UUID v4.
Se pueden encontrar más detalles sobre ULID en su documento de especificaciones.
Conclusión
En general, podemos concluir que los ULID tienden a tener ventaja en el rendimiento de escritura (en la mayoría de los casos) en comparación con los UUID, específicamente debido a la naturaleza clasificable lexicográficamente de ULID.





