


Hubo un tiempo en el que hacer SEO era bastante simple, al menos en apariencia. Consistía en repetir la palabra clave suficientes veces, acumular enlaces entrantes y esperar. Las máquinas de aquel entonces eran literales; buscaban patrones de texto y contaban las menciones. Quien dijera más veces “agencia de diseño web en Barcelona” aparecía más alto en los rankings de resultados.
Después Google aprendió a leer, no solo las palabras sino la intención, el contexto y la autoridad. Es por ello que después de varias actualizaciones, Google empezó a penalizar el contenido superficial como por ejemplo con la introducción de Panda, un filtro en el algoritmo lanzado alrededor del 2011 diseñado para evaluar la calidad del contenido de las páginas web. Al poco tiempo, Google volvió a lanzar una nueva actualización, esta vez Penguin diseñada para detectar y penalizar sitios web que utilizaban técnicas de spam y linkbuilding artificial. Esto no se detuvo aquí, en 2013 apareció Hummingbird, una nueva actualización del algoritmo con el principal objetivo de interpretar el contexto y la intención de las búsquedas en lugar de hacer coincidir palabra por palabra permitiendo así proporcionar resultados de búsqueda mucho más precisos.
Pero no fue hasta 2015 que Google lanzó RankBrain, su sistema de inteligencia artificial y aprendizaje automático utilizado para interpretar el significado de las consultas de búsqueda con la posibilidad de relacionar términos novedosos o complejos con conceptos conocidos.
Cada vez que la máquina evolucionaba, las reglas cambiaban, y quienes se habían adaptado a la versión anterior tenían que volver a aprender a hablar con ella.
Nos encontramos exactamente en uno de estos momentos de cambio, solo que esta vez la máquina no solo lee, sino que también responde.
Los modelos de lenguaje como ChatGPT, Claude, Gemini, Perplexity, etc.. han introducido un nuevo actor entre la pregunta y el contenido, no indexan previamente, recuperan información en tiempo real, sintetizan una respuesta y la entregan directamente al usuario.
Aquí entra en escena un nuevo archivo en la raíz del dominio: llms.txt y como cada vez que aparece una herramienta que promete adelantarse al cambio conviene entender bien qué es, qué aporta y qué no, antes de implementarla por inercia.
Qué es llms.txt y por qué importa ahora
llms.txt es una propuesta de estándar impulsada en 2024 por el tecnólogo australiano Jeremy Howard. Su función es directa, se trata de un archivo de texto plano en formato Markdown que se ubica en la raíz del dominio y que lista las páginas más relevantes del sitio con descripciones breves pensadas para ser interpretadas por modelos de lenguaje.
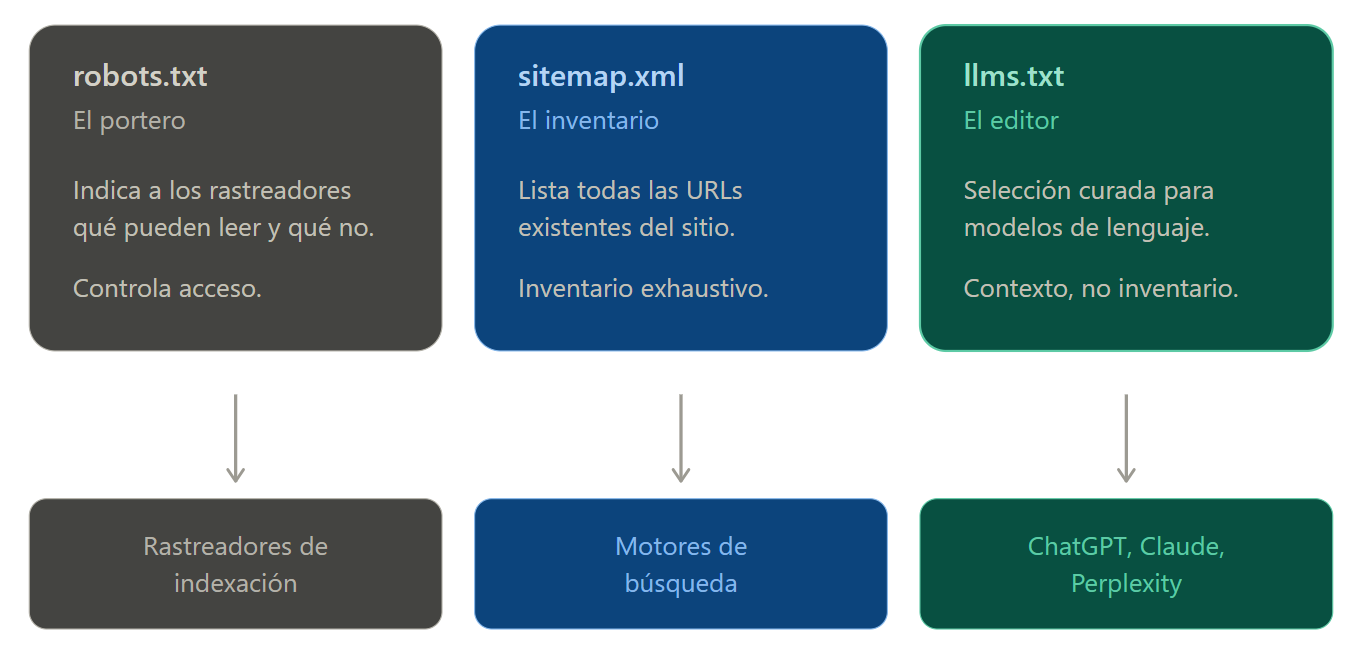
A diferencia de robots.txt, aunque ambos comparten la misma ubicación, robots funciona como un portero que indica qué puede leer un rastreador y qué no. llms no controla acceso ni bloquea nada, tampoco es un sitemap.xml que ofrece un inventario exhaustivo de todas las URLs disponibles. llms actúa como un sitemap editorial, es decir, se incluyen una selección curada de los contenidos que mejor representan el sitio.
El tráfico web ya no proviene únicamente de los buscadores tradicionales, actualmente, herramientas como Perplexity, ChatGPT Search o Claude recuperan contenido en tiempo real cuando responden a las preguntas que les hacemos. A diferencia de Google que indexa la web de antemano y consulta su índice, estos sistemas se encargan de visitar páginas en el momento exacto de cada consulta.
Aquí es donde puede aparecer un problema técnico real, una web moderna está construida para humanos. Incluye menús desplegables, animaciones de scroll, banners de cookies, contenido renderizado de forma asíncrona con JavaScript. Para un usuario esto es únicamente interfaz, pero para un modelo de lenguaje que visita la página en tiempo real, todo esto es ruido el cual repercute en el coste computacional, si el contenido realmente útil está enterrado bajo capas de presentación, el modelo lo ignora, lo malinterpreta o se queda con una versión incompleta del mensaje.
Qué aporta a Marketing y SEO
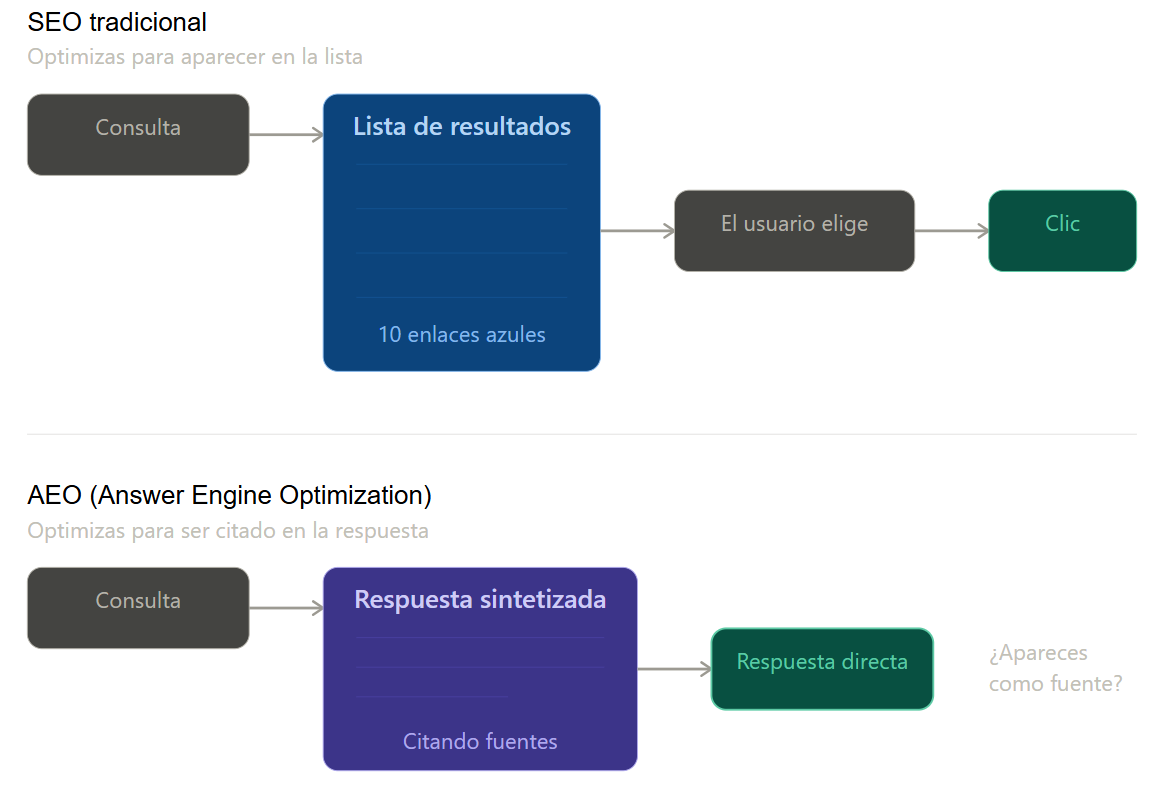
A fin de comprender el impacto estratégico de llms.txt, resulta fundamental enmarcarlo en una tendencia que está redefiniendo el sector: el AEO o Answer Engine Optimization. Mientras que el SEO de siempre se centra en la visibilidad dentro de los listados de búsqueda, el AEO busca la relevancia para ser la fuente de las respuestas que la inteligencia artificial sintetiza. Hablamos de metas diferentes que exigen aproximaciones técnicas específicas, y es aquí donde llms.txt se posiciona como una de las herramientas iniciales más tangibles para esta nueva era.
El valor no está únicamente en el archivo, sino en lo que uno debe plantearse previamente cuando desarrolla un proyecto web.
- Priorizar el contenido que realmente define la marca: debemos responder una pregunta muy concreta, Si un modelo de lenguaje únicamente pudiera leer diez páginas de nuestro sitio, ¿cuáles deberían ser? Esta pregunta nos fuerza a identificar qué activos son realmente valiosos, cuáles existen por inercia y cuáles deberían haber sido reescritos hace tiempo.
- Mejorar cómo la IA representa la marca en sus respuestas: Cuando un usuario hace una pregunta a la IA, el asistente construye la respuesta a partir de las fuentes que puede leer con más facilidad y claridad. Un sitio que ofrece una señal estructurada tiene mayor ventaja sobre uno que no lo hace.
- Reforzar la arquitectura de contenidos existente: Si no está claro que URLs incluir o cómo agruparlas, suele ser un síntoma claro de que la arquitectura de contenidos necesita una revisión.
Qué no promete llms.txt
Hay que tener en cuenta que el uso de llms.txt no promete que tu web aumente drásticamente de tráfico o conversiones. El mundo detrás de esta nueva tendencia se envuelve en el hype y es por ello que hay que tener en cuenta que las expectativas no siempre se corresponden con la realidad.
No garantiza el tráfico: llms.txt puede facilitar que un LLM cite mejor tu contenido, pero no controla si el usuario hará clic en una cita, si el modelo decidirá mencionar tu sitio en una respuesta o si la consulta se llegará a producir.
No mejora el posicionamiento en Google: John Muller, de Google, ha confirmado varias veces que la búsqueda tradicional no utiliza llms.txt como señal de ranking. El archivo se ignora a efectos de posicionamiento y no penaliza su ausencia.
No es un estándar adoptado oficialmente: a día de hoy sigue siendo una propuesta, Ni OpenAI ni Google, ni Anthropic han documentado públicamente su soporte formal.
No sustituye al SEO tradicional ni al contenido de calidad: Si el contenido es flojo, llms.txt lo único que hace es presentarlo más claramente.
¿Qué necesita el equipo técnico?
La buena noticia, a diferencia de otras optimizaciones SEO que requieren meses de trabajo coordinado entre equipos de contenido, desarrollo y marketing, es que llms.txt se implementa en horas. La estructura es deliberadamente sencilla. Un archivo Markdown con tres elementos principales: un título con el nombre del sitio, una descripción breve a modo de resumen, y una serie de secciones con enlaces y descripciones.
# Nombre del sitio
> Descripción breve de la organización o proyecto (2-3 líneas
> que definan qué hace y para quién).
## Sección principal
- [Título de la página](https://tusitio.com/pagina): Descripción concreta de qué contiene y por qué es relevante.
- [Otra página](https://tusitio.com/otra): Descripción.
## Recursos opcionales
- [Documentación técnica](https://tusitio.com/docs): Para equipos que integran la API.
Criterio de selección de URLs. Esto no es un sitemap. Incluir 200 páginas elimina el valor del archivo y satura el contexto del LLM. La recomendación general es entre 10 y 30 URLs.
La descripción es el contenido real del archivo: es lo que el LLM procesa para entender la relevancia de cada URL y decidir si visitarla.
Mantenimiento sincronizado con la arquitectura real. Un llms.txt desactualizado, con URLs que redirigen, han cambiado de slug o han desaparecido del sitio, es peor que no tener archivo. Genera confusión y reduce la confianza del modelo en la fuente. El archivo debe tratarse como parte de los procesos habituales de actualización del sitio, no como una tarea que se hace una vez y se olvida.
Reglas de formato y peso. El archivo debe estar codificado en UTF-8 y mantenerse por debajo de los 100kb. Los LLMs tienen límites de contexto y un archivo saturado puede hacer que el modelo ignore la mayor parte del contenido.
¿Cuándo merece la pena su implementación?
No todos los sitios tienen el mismo incentivo para dedicar tiempo a llms.txt. Dado que el impacto directo está sin demostrar, la pregunta correcta no es "¿me dará tráfico?" sino "¿el ejercicio de hacerlo bien me aporta algo aunque el archivo nunca llegue a leerse?".
Si el sitio tiene cientos de páginas, blog frecuente, documentación técnica extensa o una base de conocimiento estructurada, llms.txt ayuda a los modelos a encontrar lo relevante sin tener que rastrear la arquitectura completa.
Proyectos donde la búsqueda conversacional ya es una realidad. Si el público objetivo usa Perplexity, ChatGPT, Claude o herramientas similares para resolver preguntas técnicas, de negocio o de evaluación de proveedores, optimizar la legibilidad del contenido para esos sistemas es coherente con dónde está realmente la audiencia.
Productos SaaS y plataformas con documentación pública. Cualquier empresa cuya documentación, guías de integración o casos de uso son consumidos activamente por desarrolladores y compradores técnicos tiene un caso especialmente claro. Estos perfiles ya están usando asistentes conversacionales para acelerar evaluaciones y resolver dudas de implementación.
Conclusión
A día de hoy, llms.txt casi nadie lo lee, ningún gran proveedor de IA lo soporta oficialmente, Google lo ha comparado con una etiqueta obsoleta, y los pocos estudios que han medido su impacto no encuentran efecto. Si alguien te lo vende como el próximo hack de SEO, desconfía porque la evidencia no está demostrada.
Nuestra recomendación no es ignorarlo, sino entenderlo, el valor no está en el archivo, sino en el ejercicio que obliga hacer. Decidir cuál es tu mejor contenido, describirlo con precisión y mantener tu arquitectura ordenada. Este trabajo mejora cómo cualquier sistema entiende tu sitio, lea o no el archivo, y es la base real de cualquier visibilidad en IA.
Un archivo superficial, generado por un plugin y olvidado, no aporta nada. Uno construido como resultado de pensar en serio qué define tu marca aporta valor incluso si el formato acaba en nada. La condición de partida sigue siendo la misma: si los fundamentos como el SEO técnico, la arquitectura de contenidos, la velocidad, el contenido no están resueltos, ahí está tu prioridad, no en un archivo experimental. El próximo capítulo del SEO se está escribiendo, pero todavía no sabemos con qué letra. Lo que no cambia, capítulo tras capítulo, es que el contenido claro, bien estructurado y genuinamente útil siempre ha sido la mejor forma de hablar con cualquier máquina. Llms.txt es, como mucho, una forma nueva de hacer algo que ya deberías estar haciendo.
Referencias







