


La elección del modelo de base de datos es clave para garantizar el mejor rendimiento en tu proyecto. La disponibilidad, consistencia y escalado son características que debes tener en cuenta. Es por ello que repasaremos los diferentes modelos de base de datos, los tipos de escalabilidad disponibles y los modelos ACID y CAP para escoger el mejor motor de base de datos que se adapte a tus necesidades.
Un poco de historia sobre bases de datos
El desarrollo de la tecnología de base de datos se puede dividir en tres eras basadas en el modelo o estructura de datos: navegación, SQL/relacional y post-relacional.
Los primeros modelos de datos de navegación como el modelo jerárquico y CODASYL, están ya en desuso en la actualidad.
Luego apareció el modelo relacional, propuesto por primera vez en 1970 al insistir en que las aplicaciones deberían buscar datos por contenido, en lugar de seguir los enlaces.
Por último, la última generación de bases de datos post-relacionales a fines de la década de 2000 se conoció como bases de datos NoSQL, ofreciendo almacenamientos muy rápidos de valores clave y bases de datos orientadas a documentos. Estas bases de datos fueron impulsadas principalmente por la aparición de aplicaciones web que estaban limitadas por los picos de escritura/lectura (E/S) para los que no se diseñaron los sistema de gestión de bases de datos relacionales (RDBMS).
¿Qué es NoSQL (no solo SQL)?
Una base de datos NoSQL es un motor de base de datos que proporciona un mecanismo para el almacenamiento y la recuperación de datos almacenados en formatos y estructuras distintos de las relaciones utilizadas en las bases de datos relacionales. Las bases de datos NoSQL han existido desde fines de la década de 1960, pero no obtuvieron el apodo de "NoSQL" hasta el aumento de popularidad a principios del siglo XXI, desencadenado por las necesidades de organizaciones como Facebook (Cassandra), Google (BigTable), y Amazon (DynamoDB). Las bases de datos NoSQL se utilizan cada vez más en big data y aplicaciones web en tiempo real.
¿Por qué usar NoSQL?
- No es un sistema de gestión de bases de datos relacionales (RDBMS).
- Los datos no estructurados como modelo de base de datos relacional pueden no ser la mejor solución para todas las situaciones.
- La velocidad de desarrollo es mayor con NoSQL, manejando toda la información en JSON.
- Brinda experiencias satisfactorias en entornos altamente distribuidos (fueron diseñadas diseñados para ello).
- Finalmente, manejan gran cantidad de datos con mucha facilidad. Siendo una gran solución para entornos como el IoT, IA, Big Data, etc.
Escalabilidad - Horizontal o vertical
El principal desafío de las bases de datos es cómo mejorar su rendimiento. Para esto hay dos tipos de escalabilidad: vertical (scale-up) u horizontal (scale-out).
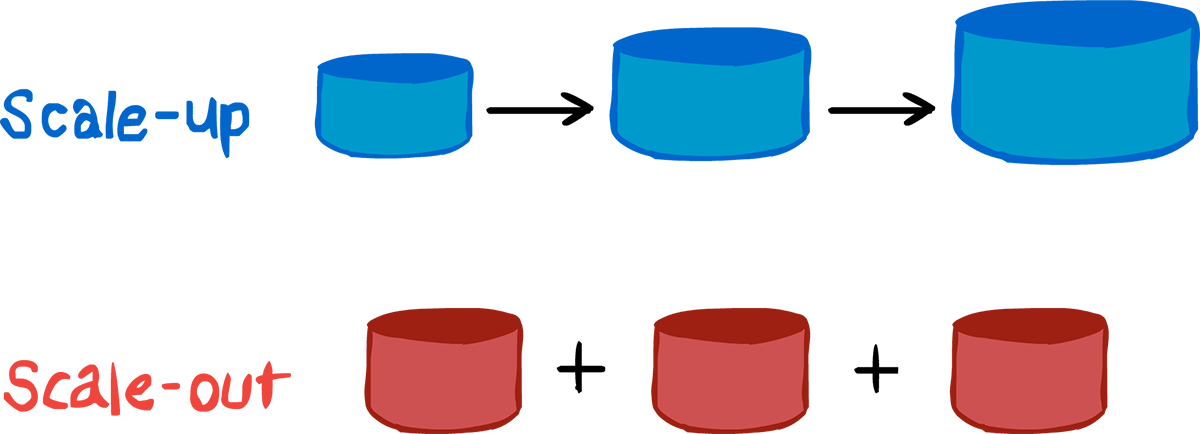
Escalado vertical: Actualizando las características del servidor de tu base de datos. Has de tener cuidado, ya que si sigues escalando, llegarás a encontrarte con cuello de botella, la ampliación de características de tu servidor puede llegar a ser finita tanto en hardware como en presupuesto.
Escalado horizontal: crea entornos master/slave. Por ejemplo, puedes balancear las peticiones enviando la inserción de datos al servidor principal “master” y las lecturas de datos al servidor esclavo. Pero, ¿qué sucede cuando el esclavo no puede ponerse al día con las escrituras? Debido a esta particularidad, apareció la replicación master/master y la fragmentación.
Fragmentación: un fragmento es una partición horizontal de datos en una base de datos. Cada partición individual se conoce como un fragmento. Cada fragmento se mantiene en una instancia de servidor de base de datos separada, para distribuir la carga. La instancia del servidor en la que se almacenan los datos está determinada por una clave específica derivada de los datos a almacenar para poder estructurar así toda la información.
Modelo ACID
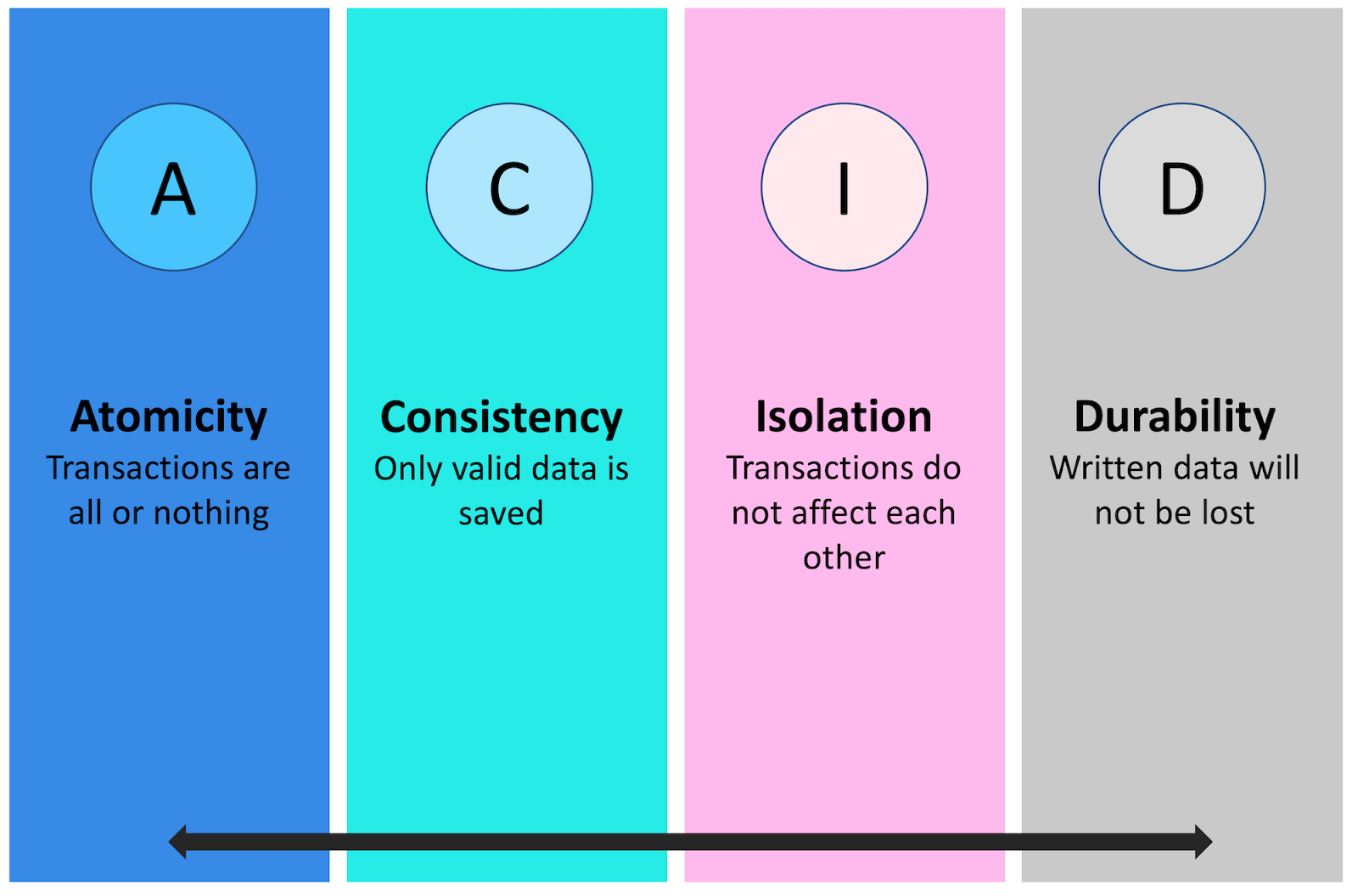
El modelo ACID de diseño de bases de datos es uno de los conceptos más antiguos e importantes de la teoría de bases de datos. Establece cuatro objetivos que cada sistema de administración de bases de datos debe esforzarse por lograr: atomicidad, consistencia, aislamiento y durabilidad.
Atomicidad
Atomicity establece que las modificaciones de la base de datos deben seguir una regla de "todo o nada ". Se dice que cada transacción es "atómica". Si una parte de la transacción falla, la transacción completa falla. Es fundamental que el sistema de administración de la base de datos mantenga la naturaleza atómica de las transacciones a pesar de cualquier sistema de gestión de bases de datos relacionales, sistema operativo o fallo de hardware.
Consistencia
La consistencia indica que solo se escribirán datos válidos en la base de datos. Si por alguna razón, se ejecuta una transacción que viola las reglas de consistencia de la base de datos, la transacción completa se revertirá y la base de datos se restaurará a un estado consistente con esas reglas. Por otro lado, si una transacción se ejecuta con éxito, llevará la base de datos al nuevo estado consistente con las reglas.
Aislamiento
El aislamiento requiere que las transacciones múltiples que ocurren al mismo tiempo no afecten la ejecución del otro. Por ejemplo, si Joe emite una transacción contra una base de datos al mismo tiempo que Charles emite una transacción diferente, ambas transacciones deberían operar en la base de datos de manera aislada. La base de datos debe realizar la transacción completa de Joe antes de ejecutar la de Charles o viceversa. Esto evita que la transacción de Joe lea datos intermedios producidos como un efecto secundario de parte de la transacción de Charles que eventualmente no se comprometerá con la base de datos. Ten en cuenta que la propiedad de aislamiento no garantiza qué transacción se ejecutará primero, simplemente que las transacciones no interferirán entre sí.
Durabilidad
La durabilidad asegura que cualquier transacción comprometida con la base de datos no se perderá. La durabilidad se garantiza mediante el uso de copias de seguridad de la base de datos y registros de transacciones que facilitan la restauración de transacciones comprometidas a pesar de cualquier fallo de software o hardware.
¿Todos los modelos de bases de datos están basados en ACID?
Ojo, aunque el modelo ACID sean los conceptos básicos para cualquier modelo de base de datos, las bases de datos NoSQL no proporcionan todos los conceptos de ACID, ya que su objetivo se basa en ofrecer respuesta con la máxima velocidad teniendo en cuenta que se pueda asumir alguna pérdida de datos. Es por ello que los conceptos ACID no aplican a todos los modelos de base de datos se definió el teorema CAP.
Teorema CAP
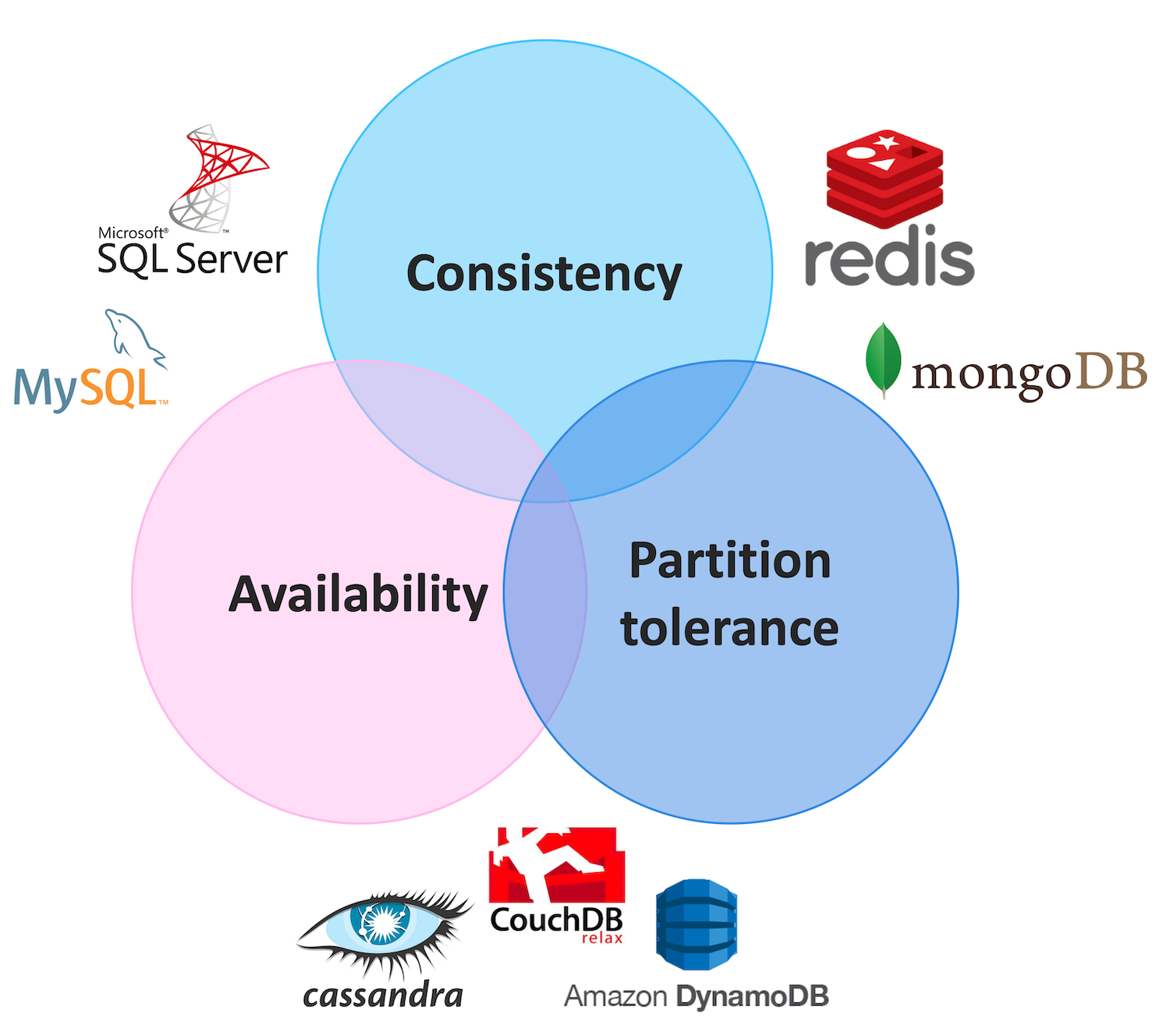
A diferencia del modelo ACID, el teorema de CAP, también denominado teorema de Brewer, establece que es imposible que un almacén de datos distribuido proporcione simultáneamente más de dos de las tres garantías:
- Consistencia: cada lectura recibe la escritura más reciente o un error
- Disponibilidad: cada solicitud recibe una respuesta (sin error), sin la garantía de que contiene la escritura más reciente. La disponibilidad del teorema CAP entra en conflicto con la “Atomicidad” del modelo ACID.
- Tolerancia de partición: el sistema continúa funcionando a pesar de que la red deje caer (o retrasa) un número arbitrario de mensajes entre nodos. La tolerancia del teorema CAP entra en conflicto con el “Aislamiento” del modelo ACID.
En caso de un fallo de red en tu base de datos, el teorema de CAP implica elegir entre consistencia y disponibilidad. ¡Ten en cuenta que la consistencia, como se define en el teorema de CAP, es bastante diferente de la consistencia garantizada en ACID!
Cuando ocurre un fallo en la red, deberíamos decidir entre:
- Cancela la operación y, por lo tanto, disminuir la disponibilidad, pero garantizar la coherencia. Esta solución es las que se ofrecen en modelos de base de datos relacional como MySQL, Oracle o SQL Server.
- Continua con la operación y, por lo tanto, brindando disponibilidad pero arriesgando inconsistencia de datos. En este caso podemos pasar a utilizar un modelo NoSQL con soluciones como Redis o MongoDB.
- Continua con la operación sin importarnos en absoluto la consistencia de datos. En este caso podemos pasar a utilizar un modelo NoSQL con soluciones como Cassandra, CouchDB o DynamoDB.
Conclusión
Como hemos analizado, deberás evaluar qué modelo de bases de datos se adapta a tu proyecto dependiendo de la consistencia, disponibilidad y tolerancia a fallos de tu aplicación. Si tu aplicación por ejemplo se trata de un software de gestión económica, sin duda deberás implementar una solución como MySQL, garantizando la coherencia de los datos. Si por el contrario requieres guardar información de un dispositivo IoT que continuamente está enviando y consultando información podrías implementar una solución de base datos como DynamoDB. O si tu caso se trata de manejar gran información de datos para el análisis o datos volátiles tu solución es MongoDB.
¿Que modelo de base datos aplicas en tus servicios? ¿Con qué motor de base datos? ¿Escalas horizontal o vertical?
Referencias:





